Store oppdateringer i MyHeritage DNA Matching

Vi gleder oss over å annonsere at vi har gjort store oppdateringer og forbedringer i DNA-matchingen vår. Alle som har tatt en MyHeritage DNA-test, og alle som har lastet opp DNA-data fra andre kilder vil nå få mer presise DNA matcher – flere matcher (rundt 10 ganger flere), færre falske positive matcher og mer spesifikke og riktige relasjonsestimater. Vi har også lagt til en lenge etterspurt»Chromosome Browser»-funksjon.
Hva er DNA Matching?
MyHeritage DNA har nå 1.075.000 mennesker i sin DNA-database. DNA Matching sammenlikner DNA-settene i MyHeritage-databasen med hverandre for å finne slektninger, det vil si individer som deler DNA-segmenter med hverandre, og for å forklare hvordan disse personene er relaterte. Tilstedeværelsen av delte DNA-segmenter mellom to personer kan indikere et slektsskap, noe som betyr at de delte segmentene ble arvet fra en felles forfader. Hvis de delte segmentene er mange og store, er et slektsskap mer sikkert. Hvis de delte segmentene er små i antall og størrelse, kan det også være en tilfeldighet, noe som tyder på at det ikke er noe slektsskap i det hele tatt. Når en match er rapportert uten at det er en slektning i det hele tatt, kalles dette en «falsk positiv».
Hvis du har tatt en MyHeritage DNA-test og fått resultatene, eller lastet opp DNA-dataene dine til MyHeritage, vil du ha fått en liste over DNA-matchene dine. Disse oppdateres daglig, og brukerne blir varslet av en ukentlig e-post om de beste nye matchene fra uken som har vært. Med «best» mener vi at matchene som har den største mengden delt DNA, som indikerer et nærmere forhold. Listen over DNA Matches viser enkeltpersoner som deler DNA-segmenter med deg, mengden og prosentandelen av DNA du deler, antall DNA-segmenter du deler, og størrelsen på det største delte segmentet. MyHeritage estimerer også forholdet ved å analysere antall og størrelse på de delte DNA-segmentene i hver match og sammenligner dem med en referansepool med hundrevisusvis av andre matcher med kjente relasjoner i henhold til familietrær som ble bekreftet av DNA. DNA Match Review Page tilbyr spor som du kan følge med på for å spore din slekt tilbake til dine felles forfedre.
Etter våre siste endringer vil brukere som har mottatt DNA Matcher få endrede og forbedrede matcher. Dette betyr at mange nye matcher vil vises Noen som eksisterte før, som var falske positive, vil forsvinne. Mange vil se endringer i sine parametere, for eksempel mengde delt DNA, til mer nøyaktige verdier.
Hvordan fungerer DNA-matching?
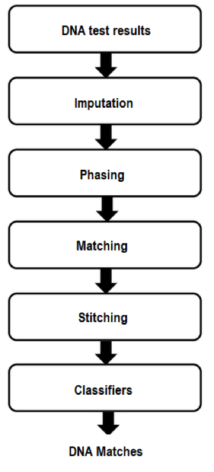
Prosessen starter når du tar en DNA-test og sender prøven til laboratoriet. I laboratoriet leser vi DNA-et, og lager en datafil med informasjonen. Vi leser ikke alle deler av ditt DNA, som tilsvarer rundt 3 milliarder deler. Vi leser omtrent 700.000 steder i DNA som er kjent for å variere mellom individer, kalt single nucleotide polymorphisms (SNPs, uttalt «snips»). Denne metoden kalles genotyping, og den produserer en datafil som viser hver SNP som vi leser, dens posisjon i DNA, og de to genotypene vi fant der (dvs. A, T, G eller C du arvet fra hver forelder). Hvis du laster opp DNA-data fra en annen tjeneste, mottar vi datafilen med samme informasjon.
Deretter bruker vi en teknikk (imputation) for å finne SNP-ene vi ikke leste. Å finne fram til DNA kan sammenliknes med å lese en setning med noen av bokstavene mangler. Det er mulig at du klarer å forstå setningen og de manglende bokstavene ut fra sammenhengen. Ikke alle DNA-tjenesteleverandører leser de samme SNP-ene. For å finne DNA-matcher for personer som har brukt forskjellige DNA-leverandører, er det viktig å forsøke å finne SNP-ene som ikke ble lest før sammenligningen av resultatene. Noen stiller spørsmål ved bruk av denne metoden. Vi har kommet fram til at denne metoden er svært nøyaktig når den brukes riktig, og i noen situasjoner er bruken uunngåelig.
Så kommer fordelingen (phasing). I hvert par kromosomer får hver person et kromosom fra sin mor og en fra sin far. Genotypingteknologien som leser DNA-prøven, bestemmer hvilke genotyper du arver fra foreldrene dine for hver SNP, men forteller ikke hvilke varianter fra samme forelder. Fordelingen hjelper oss med å sortere dette ut. Det klynger alle varianter arvet fra én av foreldrene sammen og varianter arvet fra den andre i en annen klynge.
Det neste steget er å utføre den faktiske matchingen (matching), og sammenligne alle DNA-settene i databasen som ikke samsvar med eierne til hverandre. Denne databehandlingen skjer i et system som kalles Hadoop. Matchende identifiserer de delte segmentene mellom hvert par sett, og forholdet mellom de to individene (hvis noen) kan avgjøres. Tilgrensende delte segmenter blir så «sydd» (stitching) dersom de anses å være sammenhengende.
Til slutt bruker vi avanserte statistiske algoritmer (classifiers) for å gjennomgå DNA-matchene og avvise falske positive matcher, for å bestemme konfidensnivået av matchene som ikke ble avvist, og for å foreslå type relasjon for hver match.
Slik lager vi listen over DNA-matcher.
Hvordan har vi forbedret DNA Matchingen?
Vi har forbedret nøyaktigheten av vår teknikk for å finne SNP betydelig ved å øke antall referansegener mer enn ti ganger.
Fordelingen er rettet. Behandlingen av DNA Matcher hadde sporadiske feil i dette trinnet. Disse feilene forårsaket noen falske positiver der vi tidligere har estimert delte segmenter av svært fjerne slektninger. Det medførte også problemer der vi tidligere hadde estimert delte segmenter av nære slektninger. Vi bruker nå en bedre algoritme som løser disse feilene.
I matching-fasen har vi justert terskelen for genotypingsfeil. Teknologien som leser DNA-prøven, gjør sporadiske feil. Disse kalles genotypingsfeil. Hvis det oppstår en genotypingsfeil midt i det som skal være et delt segment mellom DNA-matcher, ser dette segmentet ikke ut til å være identisk, og det kan deles i to matchende segmenter som er mindre. Vi justerte terskelen for når vi ignorerer små feilstillinger mellom ellers samsvarende segmenter, og i stedet behandler de delte segmentene som identiske til tross for små biter som ikke stemmer overens. Denne metoden kompenserer for uunngåelige genotypingsfeil. Hvis vi ignorerer feilaktige seksjoner som er for store, vil vi ved et uhell anta at et segment deles når det egentlig ikke er det; Hvis vi ikke ignorerer feilaktige seksjoner som er resultatet av genotypingsfeil, vil vi sannsynligvis savne ekte DNA-matcher.
Den nye justeringen er strengere enn den forrige, noe som betyr at færre falske positiver vil gå gjennom.
Flere fjerne matcher er nå tillatt. Etter å ha økt nøyaktigheten av matchene og justert de ovennevnte parametrene, følte vi oss komfortable med å presentert flere fjerne matcher. Tidligere var minimum delt DNA for en match 12 cM og nå er minimum 8 cM. Dette ga sammen med de andre forbedringene en ti ganger økning i antall DNA-matcher som brukerne får.
Disse vises automatisk for alle som allerede har tatt en MyHeritage DNA-test eller har lastet opp DNA-en til MyHeritage tidligere, og for dem som gjør dette framover.
Bedre «søm» av tilstøtende segmenter. I tillegg til å kompensere for genotypingsfeil innenfor segmenter, er det nødvendig å kompensere for de gjenværende feilene mellom segmentene.
For eksempel forventes en mor og datter å ha 22 matchende segmenter i en autosomal DNA-test (unntatt kjønnskromosomet) . En hel kromosom fra hver av datterens kromosompar ble arvet fra moren hennes, og hver av de 22 autosomale kromosomene skulle derfor være et enkelt, langt matchende segment.
På grunn av fordelingsfeil blir noen ganger små deler av kromosomet som kom fra moren, utvekslet med de parallelle seksjoner som er arvet fra faren. Dette er et resultat av tekniske feil, ikke biologiske prosesser. Vi har forbedret disse feilene ved å «øke størrelsen på hullene vi syr», mens vi justerer dette nøyaktig for å unngå å innføre nye feil.
Filtrere ut falske positive. Det siste steget med DNA Matching er å filtrere ut falske positive og estimere det spesifikke forholdet mellom to personer med delte DNA-segmenter. Fordi mange av oss er etterkommere av de samme svært gamle forfedre, har vi ofte små delte DNA-segmenter med enkeltpersoner som vi ikke vurderer som slekt eller familie.
Vi har funnet en metode for å filtrere ut slike matcher, som bare er til irritasjon for slektsforskere. For å gjøre dette måler vi falske positive internt ved å se på trios – disse er sett med barn, mor og far som er testet med MyHeritage DNA-sett og mottatt resultater som har bekreftet at forholdet mellom foreldrene og barnet stemmer.
Enhver match som et barn har med en annen person, som ikke samsvarer med far eller mor, er mistenkt for å være en falsk positiv og kalles «bare barn match» (child-only match). Vi måler prosentandelen av «bare barn matcher» i alle matcher som returneres for barn i kjente trios på MyHeritage. Dette tallet er prosentandelen av mistenkte falske positive som er angitt av «bare barn matcher». Vi klarte å få tallet ned til 16-20 prosent, noe som er et godt resultat som så langt er det samme eller bedre enn andre DNA-tjenester. Våre forbedrede klassifiseringsalgoritmer har lyktes med å redusere falske positive matcher.
Vi har laget en metode som hjelper deg med å fokusere slektsforskningen på den mest effektive måten. Statistiske algoritmer kategoriserer matcher og merker disse med høy, middels og lav sannsynlighet. De sistnevnte er DNA Matcher som bør behandles med skepsis fordi de er i fare for å være falske positive. Slike matcher har vanligvis svært få, svært små delte DNA-segmenter. Vær oppmerksom på at små og mellomstore sannsynlighetsmatcher er ekskludert fra de ukentlige e-postene om nye matcher.
De nye klassifiseringene er så gode at prosentandelen av «bare barn matcher» som ikke er flagget som lav eller middels tillit, nå er mindre enn 5 prosent. Hvis matchen du vurderer er anslått å være en tremenning eller nærmere, er det så mye delt DNA at du kan være trygg på at det ikke er en falsk positiv.
Nøyaktigheten av estimeringen av forholdet til en DNA-match blir målt ved å bruke to parametere kalt tilbakekalling og presisjon. Perfekt nøyaktighet betyr både å fortelle en bruker det riktige forholdet til en DNA Match hver gang (tilbakekalling), samtidig som det foreslås det riktige forholdet og ikke et bredere spekter av mulige relasjoner (presisjon). For eksempel, hvis to personer egentlig er søsken, vil en perfekt algoritme foreslå at de er søsken, og bare det. (Imidlertid er denne teoretiske perfekte algoritmen ikke mulig biologisk på grunn av DNA-ets natur.) MyHeritage foreslår nå DNA Matcher med korrekt relasjon 93 prosent av gangene for fjerne slektninger som firmenninger og femmenninger. For nærmere slektninger er nøyaktigheten mye høyere og nær 100 prosent. Samtidig vil vi bare foreslå om to eller tre mulige relasjoner for DNA Matcher som søskenbarn eller nærmere. Tilbakekalling og presisjonen er langt bedre enn tidligere.
Vi har sammenliknet kvaliteten på vår nye DNA Match algoritme ved å sammenligne nye DNA Match lister til de som produseres av andre DNA-selskaper, og resultatene er svært like.
Enkelte spesielle populasjoner, som Ashkenazi-jøder, utgjør en unik DNA-matchutfordring.Dette kommer av det i disse populasjonene har vært mange nære slektninger som har fått barn med hverandre. Dette gjør at ikke-slektsrelaterte personer i denne befolkningen mer delt DNA enn det som forventes for ikke-slektninger ellers. MyHeritage arbeidet ekstra med klassifiseringsalgoritme ved hjelp av maskinlæring for å klassifisere Ashkenazi-relasjoner med høyere oppløsning enn noen annen DNA-tjeneste. Vi brukte denne klassifikatoren til å gi bedre avvisning av falske positiver for Ashkenazi-jøder, noe som bringer dem til det samme nivået av falske positiver som befolkningen generelt.
Hva betyr disse endringene for MyHeritage DNA-brukere?
Mer nøyaktige DNA-matcher
Omtrent 10 ganger så mange DNA-matcher
Mer konkrete og mer nøyaktige relasjonsestimater
Indikasjoner på DNA Matchens-sannsynlighetsnivå for å effektivisere slekstsforskningen
Kromosomleser
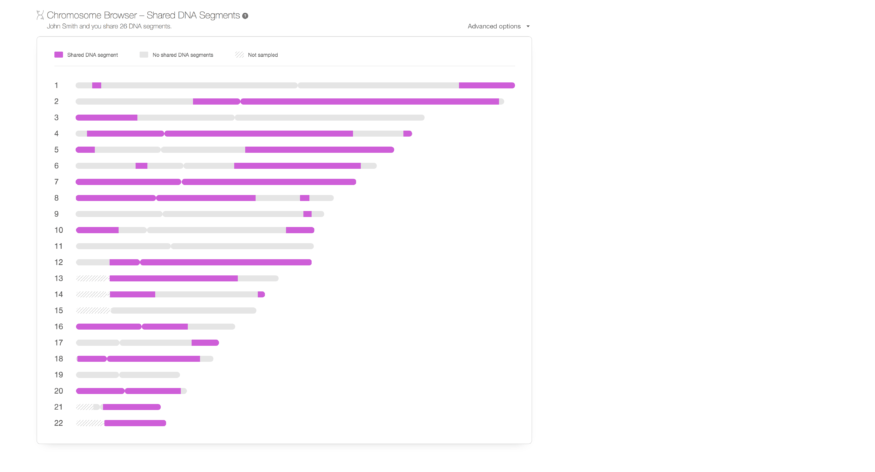
Vi har laget en kromosom-nettleser for delte DNA-matcher. Det ble lagt til på DNA Match Review-siden.

En kromosomleser er en skjematisk, visuell fremstilling av en persons kromosomer. Dette er en beta-utgave, som vil forbedres snart. Den er ment for å vise delte DNA-segmenter for enhver DNA-match. Det er en gratis funksjon som kan brukes av alle brukere på MyHeritage som har tatt DNA-testen eller opplastede DNA-data. Den viser de delte segmentene mellom deg og en DNA Match i lilla. Når du tar musen over et delt segment, kan du se den genomiske posisjonen til det delte segmentet, størrelsen på segmentet og antall SNP-er. Gråsegmenter deles ikke med DNA Match og skraverte felt ble ikke analysert på grunn av mangel på SNP.
Personverninnstilling. Vi tillater ikke at en annen bruker laster ned dine rå DNA-data. Vær likevel oppmerksom på at når en annen bruker har et delt et segment med deg, ser detaljene (posisjon og størrelse) og deretter gjennomgår segmentets informasjon om sitt eget DNA , kan den andre brukeren også utlede genotypene du har i DNA i det aktuelle segmentet. Brukere som ønsker å forhindre at andre brukere med DNA-match å se detaljene i delte segmenter, kan velge bort denne funksjonen ved å bruke en ny personverninnstilling.
På sikt tror vi at brukerne våre vil bruke den nye kromosomnettleser-funksjonen til å identifisere bestemte segmenter i deres DNA, forfedrene de oppsto fra, få bedre innblikk i DNA-matchene, og bedre forstå relasjonen mellom disse.
Enklere navigering
Som en del av denne oppdateringen har vi gjort små justeringer av brukergrensesnittet til DNA-matchene. De fleste av disse endringene er små og knapt merkbare, mens en merkbare forbedring er når man ruller ned gjennom listen over DNA-matcher, vil du aldri miste oversikten over hvilke matcher du ser på.

Arbeid pågår
Arbeidet er ikke fullført og er noe vi jobber med kontinuerlig. Samtidig med den voksende størrelsen på DNA-databasen vår og økt tilknytningen mellom DNA-sett og familietrær, ønsker vi å regelmessig optimalisere agoritmer og forbedre nøyaktigheten ytterligere.
Av hensyn til DNA-data lastet opp fra andre tjenester, støtter vi fortsatt ikke DNA-sett som er basert på Illumina GSA-brikken. Disse inkluderer DNA-sett fra 23andMe (nyere V5 versjon) og Living DNA. Vi har støtte for DNA-data fra GSA-brikker som fungerer i vårt laboratorium, men siden dette fortsatt ikke er perfekt, har vi ekskludert dette fra denne oppdateringen til vi får det perfekt. Dette vil bli lagt til i de neste månedene.
Etnisitetsestimater er skilt fra DNA Matching og forbedringene beskrevet her påvirker ikke etnisitetsestimatene. Vi planlegger en oppdatering til våre etnisitetsrapporter i de neste månedene for å forbedre nøyaktigheten også. Følg med!
Neste skritt
Bestill et MyHeritage DNA-sett til deg selv eller familien for å dra nytte av disse nye funksjonene og forbedringene, hvis du ikke allerede har gjort det. Hvis du allerede har testet deg selv og andre slektninger testes, kan du finne nye slektninger og krysse dine egne matcher. Den nye kromosom-nettleseren kommer til nytte når du skal forstå disse matchene. Hvis det er en bestemt gren i slektstreet ditt som du er mer interessert i å utforske videre, kan du kjøpe tester til flere eldre slektninger av deg i den grenen.
Hvis du allerede administrerer mer enn ett DNA-sett på MyHeritage, må du ta deg tid til å verifisere at hvert sett du administrerer er knyttet til den rette personen. Dette kan løses ved å bruke «Administrer DNA-sett» -siden fra DNA-menyen. Bruk alternativet «Videresend sett til en annen person» hvis du har et sett som ikke er riktig tilknyttet. Dette er nødvendig hvis alle DNA-settene du har lastet opp for slektninger, fortsatt er knyttet til din egen slektstreprofil.
Og til slutt: DNA-settene på MyHeritage er langt mer nyttige når det er et slektstre knyttet til dem. Hvis du har et DNA-sett knyttet til MyHeritage, men ikke noe tre eller et lite familietre, er det smart å sette det opp i forbindelse med testen. Det er nyttig for DNA-matchene dine og for deg selv.
Lykke til!
Hilsen MyHeritage-teamet








